
PhoenixDSR: Phoneme-Guided and LLM-Enhanced Dysarthric Speech Recognition
Published in ICASSP 2026, 2026
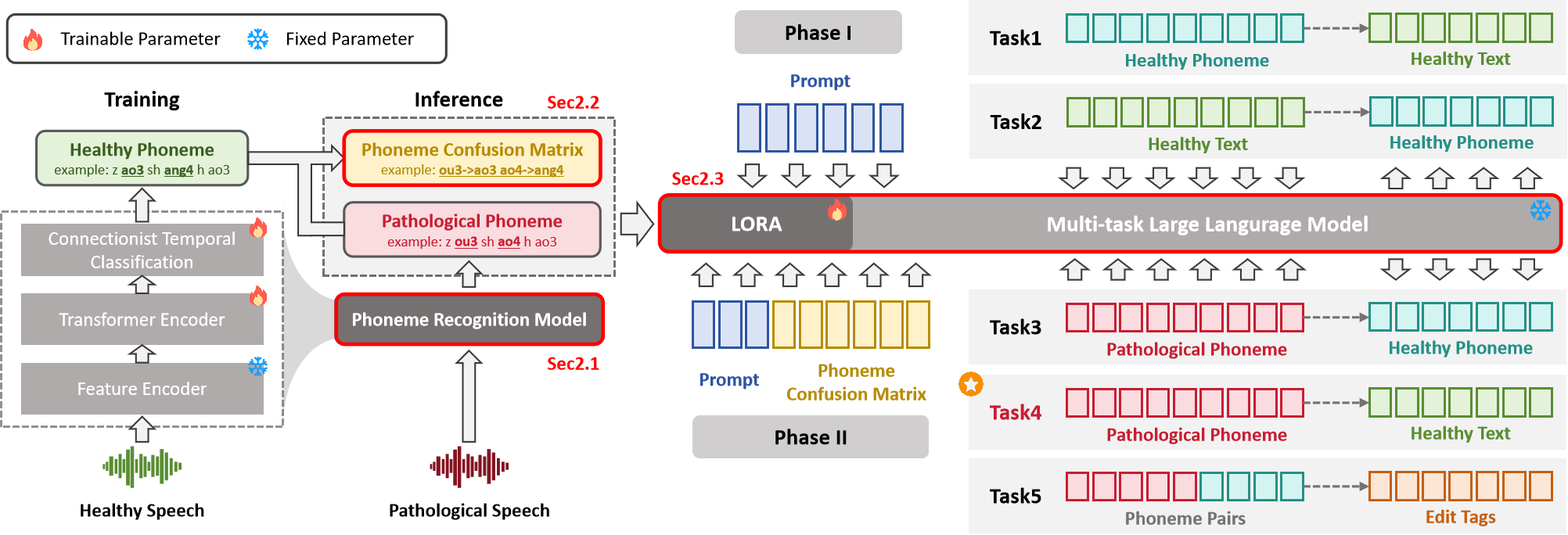
Automatic speech recognition (ASR) still struggles on dysarthric speech due to data scarcity and speaker heterogeneity. We present PhoenixDSR, a phoneme-mediated framework that decouples acoustic variability from linguistic decoding. A Wav2Vec2-CTC recognizer trained on healthy speech provides stable phoneme sequences. From limited dysarthric alignments we estimate a weighted confusion probability matrix that fuses global and speaker-specific patterns. A lightweight LLM decoder is trained on five tasks—bidirectional text–phoneme mapping, dysarthric-to-healthy normalization, phoneme-to-text decoding, and edit-operation prediction—to enable context-driven repair of systematic phoneme errors. On CDSD, PhoenixDSR attains 18.3% CER and 13.7% PER, outperforming end-to-end fine-tuning and LLM post-editing; ablations verify the importance of phonotactic pretraining and confusion priors. Few-shot personalization updates only the prior, yielding additional gains without further gradients. By combining interpretable phoneme-level priors with context-aware decoding, PhoenixDSR achieves data-efficient and robust recognition.
Recommended citation: Wu, Y., Xu, Y., Wang, J., Zhao, X., Jiang, J., & Luo, Z. (2026). PHOENIXDSR: Phoneme-Guided and LLM-Enhanced Dysarthric Speech Recognition. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).
Download Paper